Memory management
February 2025

This month, I took some time off to escape the dreary winter, but not without doing some research of course! I've visited koi ponds in Madeira. To be fair, these weren't the prettiest specimens I've ever seen. I may be spoiled after my trip to Ojiya, but I can't shake the impression that these koi weren't selected or cared for by an enthusiast. The animals themselves didn't seem to mind though.
Something I've been putting off for a while was the daunting task of building good memory management systems. The prototype used WebGPU, which takes care of most memory issues, but a custom engine requires custom memory management. That means I have to write systems that assign memory from large managed memory pools to rendering systems that need it. This can be very difficult and tedious to get right, but it's extremely important; errors in memory management can slow down rendering significantly, or simply cause random crashes that are very hard to debug and fix.
I've designed my memory manager with three main goals in mind:
- Memory that's used together, should be stored together. If I'm storing koi models all over VRAM, the GPU will spend a lot of time reading memory from all over the place. Instead, I want all fish data to be stored next to each other, and I want it to be used in the order it's stored whenever possible. This has significant performance benefits; the GPU doesn't read memory in tiny bits, but in huge chunks. If I manage memory in this way and render the first fish, the GPU loads memory containing not just that fish but a bunch of them. Drawing the next ones will not incur heavy memory access costs.
- For simplicity, I don't want to move memory around all the time. That means that memory locations, or at least locations within allocated chunks, should stay in place. That way I can store memory locations as simple offsets inside a memory pool that never change.
- At the same time, I don't want too much memory fragmentation. When a chunk of memory contains gaps of unused bytes, I'll store things in those gaps first before I start allocating more memory at the end of a chunk.
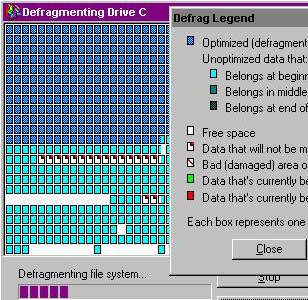
If you're also old, you may remember the mindful act of defragmenting your hard drives. Nowadays, most computers are sold with solid state drives that don't need it anymore. Defragmenting memory basically means moving pieces closer together, making more memory available for other things while also speeding up memory access because data isn't as spread out. To achieve point 3, memory management systems in games still defragment memory in the background. Some do it actively, by looking for fragmented memory and moving pieces around to keep the buffer compact; others are lazier, and just try to prioritize filling in the "bubbles" within a chunk of memory first before allocating more or resizing a buffer. I've implemented the latter method, but I may implement the first later to reduce VRAM usage a bit more.
I've encountered some other challenges:
- Vulkan only supports a limited number of allocations, so I can only request a small number of very big chunks of memory in total. That means it's not possible to request a piece of memory for every type of data I want to store, I've had to subdivide larger chunks into "themed" chunks of memory. One contains all the model vertex data, another contains all the compute shader data and so on.
- Alignment caused me headaches. The GPU needs data to be aligned properly to be able to read it. That means for example that objects that are 128 bytes large cannot be placed at an offset in memory that's not a multiple of 128 bytes. Sometimes, these memory objects are created by the CPU first in normal RAM, which has different alignment requirements.
- Buffers can not be read from and written to at the same time. The GPU works asynchronously from the CPU, so I can never know precisely what it's doing at the moment, or whether it's accessing any part of a buffer. This means I have to upload data in a number of stages, making sure I only write to unused memory, and making sure data is never read before writing has finished.
After implementing better memory management systems, my buffers could finally resize to any capacity, so I started implementing interactions amongst large groups of koi again. Since the maximum number of koi in the scene is about 4000, efficiency is crucial. By splitting my koi objects' positions from the rest of their data, the game now does an early interaction detection pass that only loads koi position data. Koi then only react with each other if the early pass indicates that they should.
I've also implemented shadow rendering. While doing this, I designed the engine in such a way that all graphics settings can be toggled at runtime. This is super useful while debugging, but I also really appreciate it when games don't require a full restart while you're playing with the settings.
The mango color palette in the screenshot is not a stylistic choice; they represent texture coordinates for patterns, which will be implemented next.